Firstly, I need to extract the audio files from the video game The Witcher 3: Wild Hunt to prepare data for training the model. Conveniently, someone else has written an application to unpack the audio files, with a dialog file. This would save me some time for exploring their file encryption.
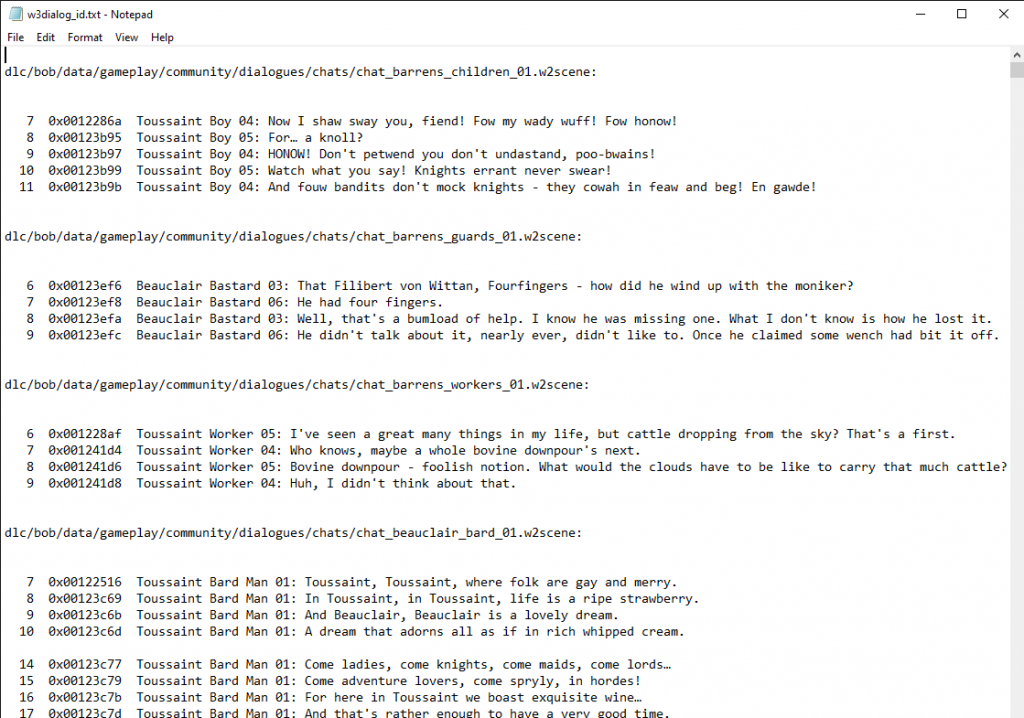
So after a very long time, the files are here, but they are totally unorganized and I don’t know which files belong to which person. That’s why there was a txt file mentioning the corresponding dialog.
Time to do some coding…
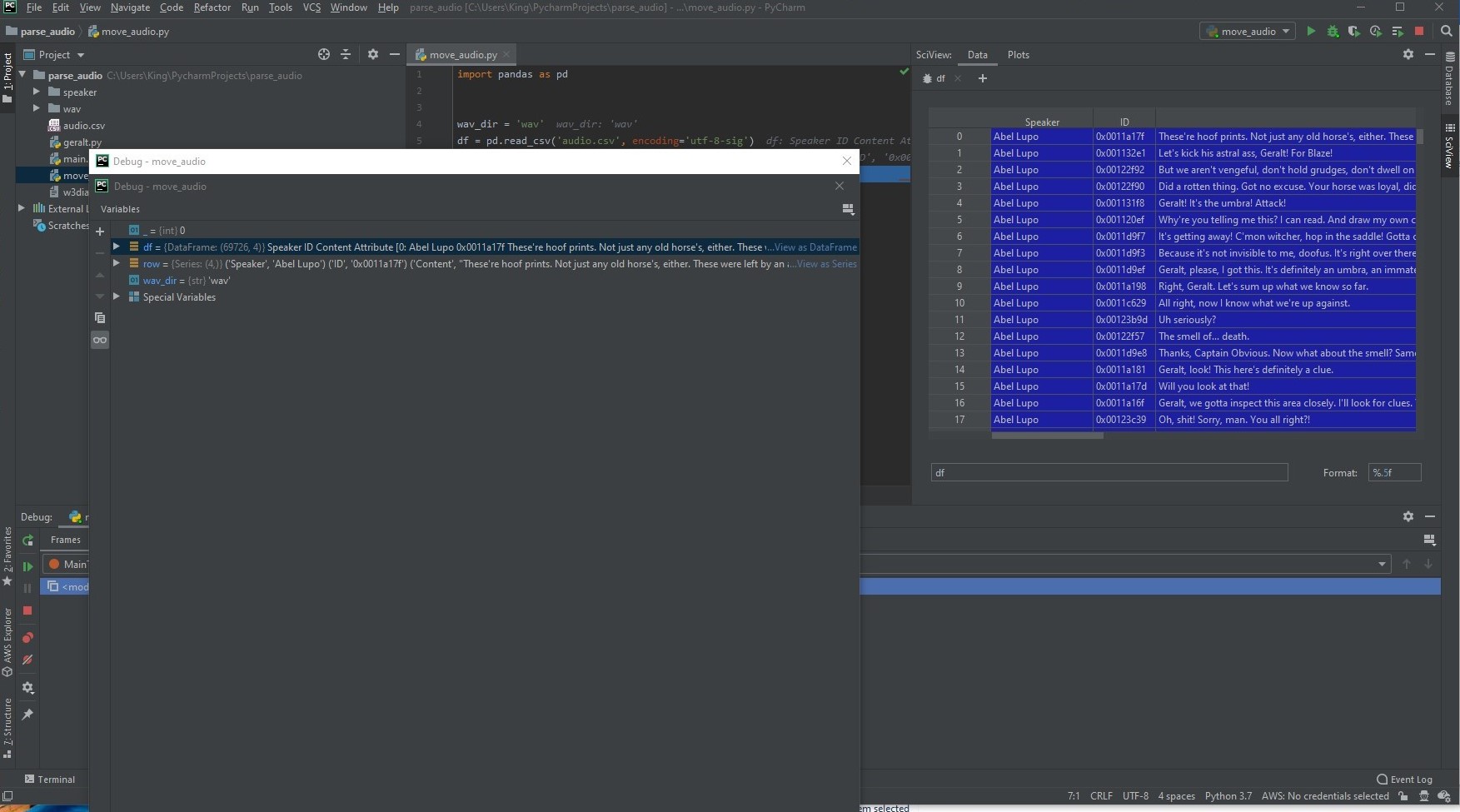
It was the first version, later I’ve decided to add the scenes as well (Because some scenes have drunk audios, don’t want the model sounds drunk :))
import re
import pandas as pd
import csv
with open('w3dialog_id.txt', 'r', encoding='utf-8') as f:
audio_list_file = f.read()
audio_list = [re.sub(r'^\s+', '', x) for x in audio_list_file.split('\n') if x]
audio_list = [x for x in audio_list if x[0].isalpha() or x[0].isnumeric()]
data = []
current_scene = ''
for x in audio_list:
if x[0].isalpha():
current_scene = x.split('/')[-1].split('.')[0]
else:
content_id, audio_id, audio_string = re.split(r'\s+', x, 2)
char, content = audio_string.split(': ', 1)
data.append([char, audio_id, current_scene, content_id, content])
df = pd.DataFrame(data, columns=['Speaker', 'Audio', 'Scene', 'ID', 'Content'])
df.drop_duplicates('Audio', inplace=True)
df.to_csv('audio.csv', index=False, encoding='utf-8', sep='|', quoting=csv.QUOTE_NONE)
print('done')It is pipe-delimited, and there is no quote escape because I wanted to follow the sample LJSpeech dataset CSV file.
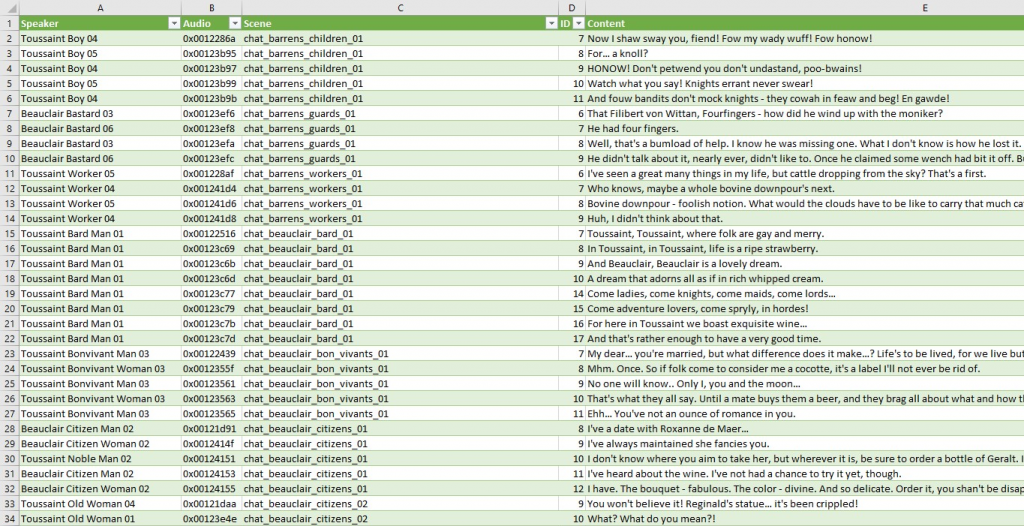
After it has been converted into a csv, the file moving part can start.
import pandas as pd
import os
import logging
from datetime import datetime
wav_folder = 'wav'
speaker_folder = 'speaker'
now = datetime.now()
logging.basicConfig(filename=f'Error_{now.strftime("%Y-%m-%d_%H:%M:%S")}.log', filemode='w', level=logging.DEBUG)
df = pd.read_csv('audio.csv', encoding='utf-8', sep='|')
for _, row in df.iterrows():
if not os.path.exists(f'{speaker_folder}/{row["Speaker"]}'):
os.makedirs(f'{speaker_folder}/{row["Speaker"]}')
try:
os.rename(f'{wav_folder}/{row["Audio"]}.wav.ogg.wav', f'{speaker_folder}/{row["Speaker"]}/{row["Audio"]}.wav')
except FileNotFoundError:
logging.warning(f'{row["Audio"]} is not found!')
print('done')Just wanted to log some files, indeed some files are missing.

And I’ve written an extra script to add a column indicating their existence.
import pandas as pd
import os
import csv
speaker_folder = 'speaker'
df = pd.read_csv('audio.csv', encoding='utf-8', sep='|', quoting=csv.QUOTE_NONE)
df['Exist'] = df.apply(lambda x: os.path.isfile(f'{speaker_folder}/{x["Speaker"]}/{x["Audio"]}.wav'), axis=1)
df.to_csv('audio.csv', index=False, encoding='utf-8', sep='|', quoting=csv.QUOTE_NONE)
print('done')And finally, to separate the file with the speaker name as the respective csv filenames.
import pandas as pd
import os
import csv
output_folder = 'separated'
if not os.path.exists(output_folder):
os.makedirs(output_folder)
df = pd.read_csv('audio.csv', encoding='utf-8', sep='|', quoting=csv.QUOTE_NONE)
for speaker, speaker_df in df.groupby('Speaker', sort=False):
speaker_df.to_csv(f'{output_folder}/{speaker}.csv',
index=False, encoding='utf-8', sep='|', quoting=csv.QUOTE_NONE)
print('done')
Then, time to do some natural language processing to the csv files!