Looking at LJSpeech dataset, there is a column called:
Normalized Transcription: transcription with numbers, ordinals, and monetary units expanded into full words (UTF-8).
Here are some sample sentences from Geralt, the main character:
Need Form 202 to get a copy of Permit A38. D’you know that? Couldn’t have told me? Wasted a lot of time because of you.
Vintages from 1255 to 1264…
So they are pronounced sometimes as years, sometimes numbers, sometimes pure number. Quite tricky.
And here are some dialogues from Yennefer, the other main character.
Celain, celain, deffraen!
Celain, celain, davedar!
Okay… That’s not usable, plus the sounds are actually post-processed with SFX.
So I need to identify spells as well. I don’t want to check 1000+ rows… Good thing that they are not really English. Maybe a language detection library could solve this tiny problem?
And the other thing is about the punctuation, some punctuation are… over-exaggerated. They have the same pause as a comma, but it’s just differently represented in the game. Not really good to be generalized using lots of punctuation.
I took a look at the dctts PyTorch implementation, the vocab list is just all lower alphabets, space, full stop, apostrophe, and a question mark. Even though the comma is not there, I feel like I should add the comma if I am to train my own model. Hence, I’ve decided to add a comma and exclamation mark. So the rest needs to go away… No, they should be replaced by comma as much as possible since there is still pause. Actually it might not be the effect of pause, but how the intonation changes before comma. So punctuation in the dialogues like (…, – , !?, ?!) are some changed to comma, some full stop, depends on their position.
nlp.py
# SM4701 SIU KING WAI 54412743
from num2words import num2words
from unidecode import unidecode
import re
import fasttext
import spacy
from spacy.tokenizer import Tokenizer
from spacy_syllables import SpacySyllables
from spacy_cld import LanguageDetector as cld
from spacy_langdetect import LanguageDetector as langdetect
lang_model = fasttext.load_model("lid.176.bin")
# All the nlp pipelines
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe(cld())
nlp.add_pipe(langdetect(), name='language_detector', last=True)
tokenizer = Tokenizer(nlp.vocab)
syllables = SpacySyllables(nlp)
nlp.add_pipe(syllables, after='tagger')
def tag_and_process(text):
# regular expressions for various steps
attr_list = [
[r'\d', 'D'], # Digits
[r'\*', 'A'], # Action
[r'-{2}', 'U'], # Unfinished
[r'\?', 'Q'], # Question
[r'!', 'E'], # Exclamation
[r'\.\.\.|…', 'S'], # Sigh
[r'[\w\s]-[\w\s]', 'H'] # Hyphen
]
replace_list = [
[r'\?!', '?'],
[r'\*(.+?)\*', ''],
[r'^(\.\.\.|…)', ''],
[r'"(\.\.\.|…)', '"'],
[r'(\.\.\.|…)$', '.'],
[r'(\.\.\.|…)"', '.'],
[r'(\.\.\.|…)\?', '?'],
[r'(\.\.\.|…)!', '!'],
[r'\.\.\.|…', ', '],
[r'--$', '.'],
[r' - ', ', '],
[r'-- ', ', '],
[r' \.', '. '],
[r'--\?', '?'],
[r'Vol\.', 'Volume ']
]
num_replace_list = [
[r'202', 'two-oh-two'], # just this one specifically
[r'\d(?:st|nd|rd|th)', lambda x: num2words(x.group()[:-2], to='ordinal')],
[r'[12][0-9]{3}', lambda x: num2words(x.group(), to='year')],
[r'\d+', lambda x: f' {num2words(x.group())}'],
[r' \d+', lambda x: num2words(x.group())]
]
# Replacing
attr = ''.join([tag for regex, tag in attr_list if re.search(regex, text)])
processed_text = unidecode(text) # Get rid of the accented characters
for regex, replacement in replace_list:
processed_text = re.sub(regex, replacement, processed_text)
if 'D' in attr:
for regex, replacement in num_replace_list:
processed_text = re.sub(regex, replacement, processed_text)
# Finalize
processed_text = re.sub(r'\s+', ' ', processed_text).strip()
# NLP stuffs
doc = nlp(text) # for detecting language in raw text
tokenized = tokenizer(processed_text) # for word counts
syllables_count = sum(filter(None, [token._.syllables_count for token in nlp(processed_text)])) # for syllables
return \
processed_text, \
attr, \
len(tokenized), \
syllables_count, \
lang_model.predict(text)[0][0][9:], \
lang_model.predict(processed_text)[0][0][9:], \
','.join(doc._.languages), \
','.join(tokenized._.languages), \
doc._.language['language'], \
tokenized._.language['language']util.py
# SM4701 SIU KING WAI 54412743
import os
import re
import csv
import sys
import librosa
import pandas as pd
from pandarallel import pandarallel
from nlp import tag_and_process
pandarallel.initialize()
def get_parameter():
try:
return sys.argv[1]
except IndexError:
print('Please specify file name')
sys.exit(1)
class WitcherData:
wav_folder = '' # The directory that contains the character wav files
def __init__(self, filename):
self.filename = os.path.splitext(filename)[0] if 'csv' in filename else filename
self.df = pd.DataFrame()
@staticmethod
def change_wav_folder(folder_name):
folder_name = re.sub(r'/$', '', folder_name)
WitcherData.wav_folder = f'{folder_name}/'
def read_file(self, tag=''):
filename = f'{self.filename}_{tag}' if tag else self.filename
# fillna incase of missing string(np.nan = float), for filter step
self.df = pd.read_csv(f'{filename}.csv', encoding='utf-8', sep='|', quoting=csv.QUOTE_NONE).fillna('')
def save_file(self, tag='', export=False, index=False, header=False, mask_exp='', export_dir=''):
df = self.df
if mask_exp:
df = df[eval(mask_exp)]
if export:
df = df[['Audio', 'Content', 'Processed']]
if export_dir:
export_dir = re.sub(r'\/$', '', export_dir) + '/'
filename = f'{self.filename}_{tag}' if tag else self.filename
df.to_csv(f'{export_dir}{filename}.csv', encoding='utf-8', index=index, header=header, sep='|', quoting=csv.QUOTE_NONE)
def check_audio(self):
self.df['Exist'] = self.df['Audio'].parallel_apply(
lambda audio: os.path.isfile(f'{WitcherData.wav_folder}{self.filename}/{audio}.wav'))
def get_audio_length(self):
self.df['Duration'] = self.df['Audio'].parallel_apply(
lambda audio: librosa.get_duration(filename=f'{WitcherData.wav_folder}{self.filename}/{audio}.wav'))
def analyze_text(self):
self.df[
'Processed'
], self.df[
'Attribute'
], self.df[
'Count'
], self.df[
'Syllables'
], self.df[
'fasttext'
], self.df[
'fasttext_processed'
], self.df[
'cld2'
], self.df[
'cld2_processed'
], self.df[
'langdetect'
], self.df[
'langdetect_processed'
] = list(zip(*self.df['Content'].parallel_apply(tag_and_process).to_list()))
def filter_scene(self):
"""Scenes to be filtered out"""
if self.filename == 'Geralt':
# filter out those drunk scenes with unclear audio
scenes = ['q401_06_04_reunion_part_02',
'q401_06_07_gmpl_finding_drunk_eskel',
'q401_06_08_found_drunk_eskel',
'q401_06_09_calling_ida_drunk']
self.df = self.df[~self.df['Scene'].isin(scenes)]
def filter_exist(self):
self.df = self.df[self.df['Exist']]
def filter_lang(self):
is_eng = self.df.parallel_apply(
lambda row: any(['en' in row[col] for col in ['fasttext',
'fasttext_processed',
'cld2',
'cld2_processed',
'langdetect',
'langdetect_processed']]),
axis=1
)
self.df = self.df[is_eng]
def drop_info(self):
self.df.drop(['Speaker', 'Exist', 'ID'], axis=1, inplace=True)To use the modules:
# SM4701 SIU KING WAI 54412743
from util import WitcherData, get_parameter
if __name__ == '__main__':
data = WitcherData(get_parameter())
data.read_file(tag='processed')
data.check_audio()
data.filter_exist()
data.filter_scene()
data.get_audio_length()
data.drop_info()
data.analyze_text()
data.filter_lang()
data.save_file(tag='processed', header=True)
print('Preprocess done.')And here are some before and after:
Whaddaya mean, “wrong window”?! I was told I’d get Permit A38 here.
Whaddaya mean, “wrong window”? I was told I’d get Permit A thirty-eight here.
Strangled… by an expert. Round up some men and bury him outside the village. Deep, so the corpse eaters don’t get at him. And take my advice… don’t mention any of this to the Nilfgaardians.
Strangled, by an expert. Round up some men and bury him outside the village. Deep, so the corpse eaters don’t get at him. And take my advice, don’t mention any of this to the Nilfgaardians.
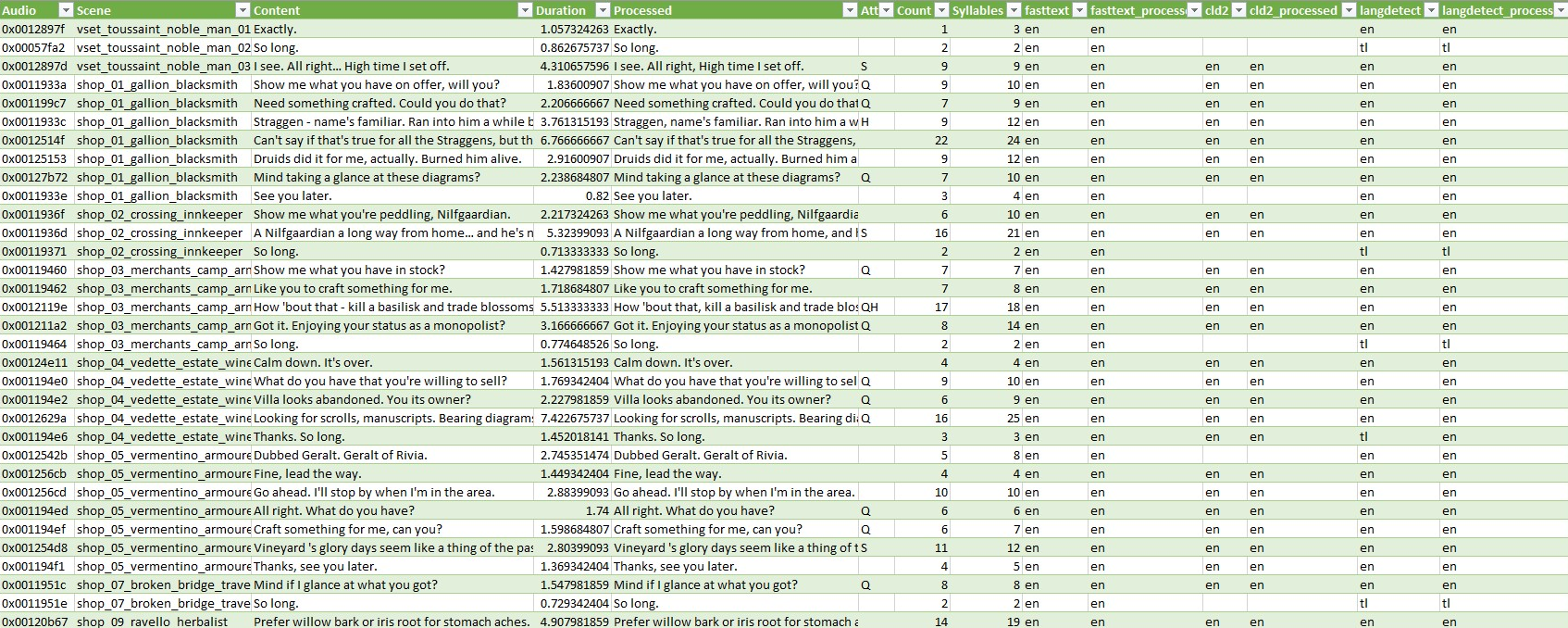
You can see from the script that I’ve used several language detection models, while fastText is the most accurate one, it sometimes actually do it too well and misclassify some sentences with extra punctuation as non-English, that was compensated by other model. In the end, I keep sentence with at least one of the language models detected as English.
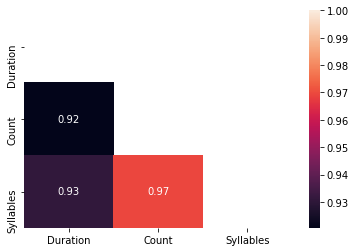
In order to increase training quality, I’ve decided to remove sentences that has less than 5 words. Later doing some data analysis on a Jupyter notebook, I realized I should be looking at the syllables instead. Syllables turns out has a better correlation to the duration of the audio clips than word counts. (Make sense)
Some diagrams from the notebook:
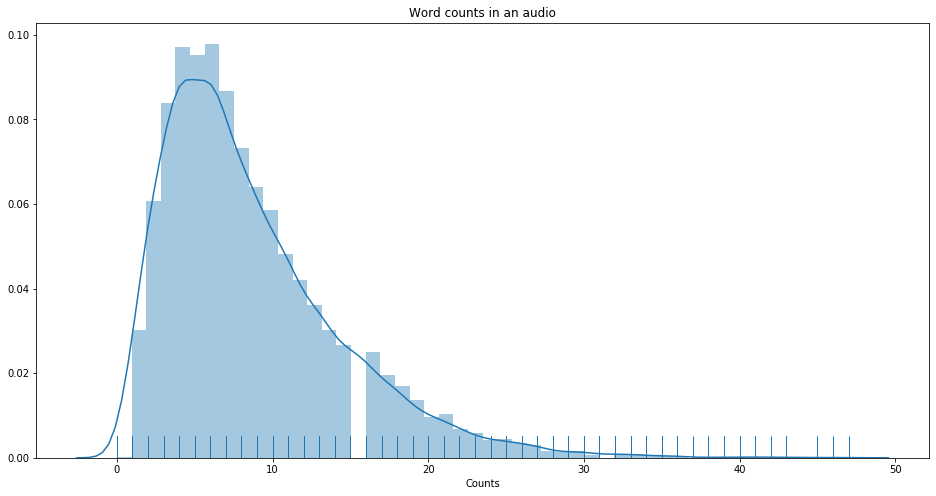
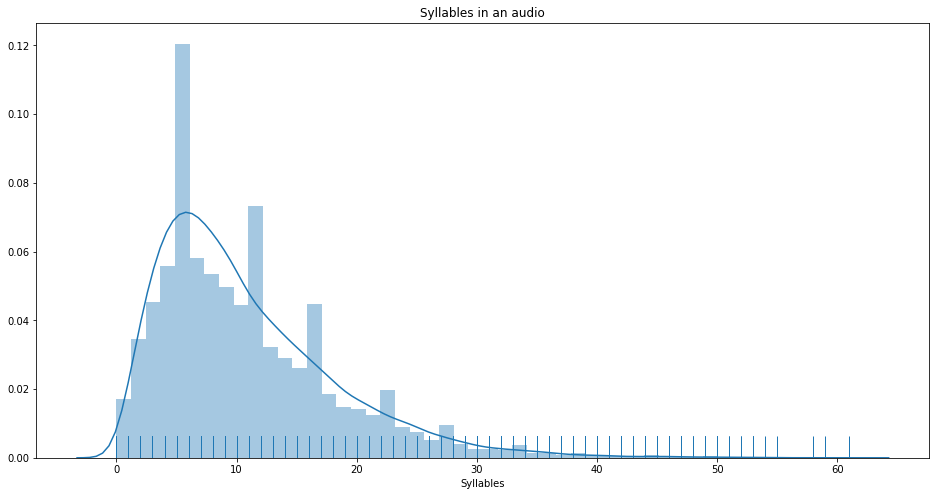
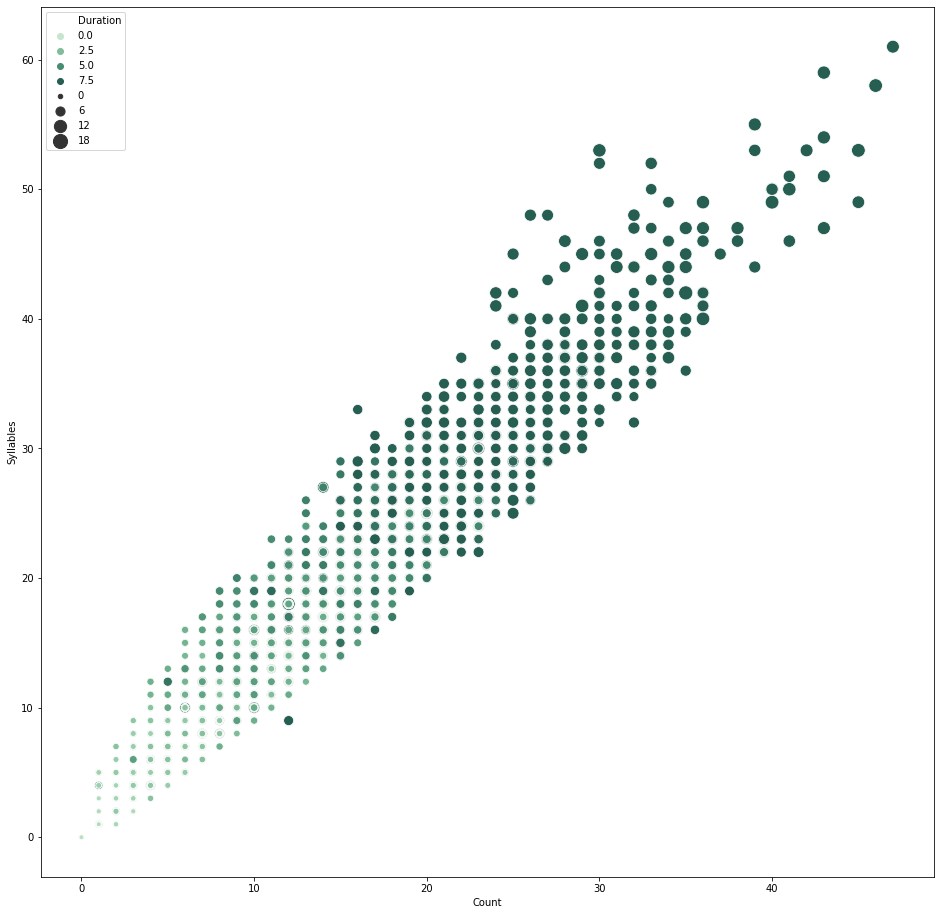
Pearson Correlation
Another notebook for Yennefer.