It wasn’t until I started testing a whole chapter from the book that I realized there’s an extreme flaw in my program.
- The previous testing includes multiple speaker, therefore the clips are separated. It’s not the case when there’s a single speaker
- The ‘base’ video and ‘animated’ video are all stored in memory as numpy array. Which takes up a huge amount of memory and easily triggers SIGKILL(out of memory, not vram kind)
- For the VRAM, It also becomes a problem during the ‘base’ and ‘animate’ phase. The audio synthesis seems to be fine, but when a long duration of audio needs to be animated, the video memory gets full easily
Well, it wasn’t incurable, so I think of something to solve it.
I implement a size checking part when creating the wav_dict, which combines audio clips into chunks. The wav_dict didn’t really divide the audio when it’s the same speaker, so I added an extra condition in the if statement that handles the cutting part. Previously, it cuts when it detects the new element is a new speaker, now it detects the accumulated array size. Therefore, when the audio is too long, it will divide it as a new speaker would.
from:
if last_speaker != sentence_dict['speaker']:to: (where cut_size is default to be 800000, i.e. 800000/22050 = 36.3s)
if last_speaker != sentence_dict['speaker'] or sum(len(wav) for wav in wavs_dict['wav']) > cut_sizeAnd of course its not an exact hard cut-off, because that would make the audio stops suddenly and not being able to be animated. So it only triggers when the accumulated list of items has exceeded the cut_size.
The other thing is to not store the video as arrays, when the audio is animated, the result should be exported to the disk as a temporary file so that it doesn’t take up the memory.
Firstly, during the ‘base’ phase, that the audio is animated with the speech-driven animation model, since the arrays are still needed for the first-order model, it’s not directly converted to a video, but stored as a NumPy array file.
The base is stored as NumPy arrays with a filename using | as a separator to indicate the speaker.
np.save(f'temp/base/{i}|{wavs_dict["speaker"]}.npy', va('data/sda/image.bmp', wavs_dict['wav'], fs=hp.sr))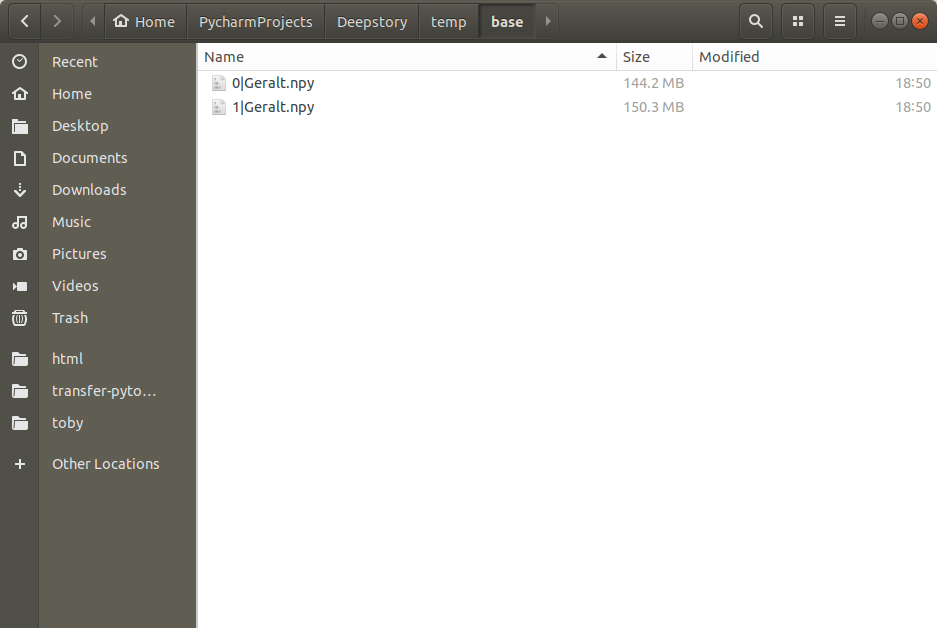
Secondly, I’ll have to directly save the animated video from first-order model to a video file direct.
I made changes to .animate_image() method from the animator class, so that it doesn’t return a video array but but save the video array directly to video only clips inside a temp folder.
There was also something that was not memory efficient from the original code that I didn’t modify.
From this:
predictions.append(np.transpose(out['prediction'].data.cpu().numpy(), [0, 1, 2, 3])[0])to this:
out['prediction'] *= 255
out['prediction'] = out['prediction'].byte()
predictions.append(out['prediction'].permute(0, 2, 3, 1)[0].cpu().numpy())From the code, I’ve multiplied the video array by 255 and then cast to to uint8 so that I don’t have to do it again like the original code did:
[img_as_ubyte(frame) for frame in predictions]Then I also do all the permutation and selection when it is still a tensor, and only transfer it to cpu memory when it is done.
And because imported the imageio in the animator class, I also use its save video function. (fps is 25 from sda)
imageio.mimsave(output_path, predictions, fps=25)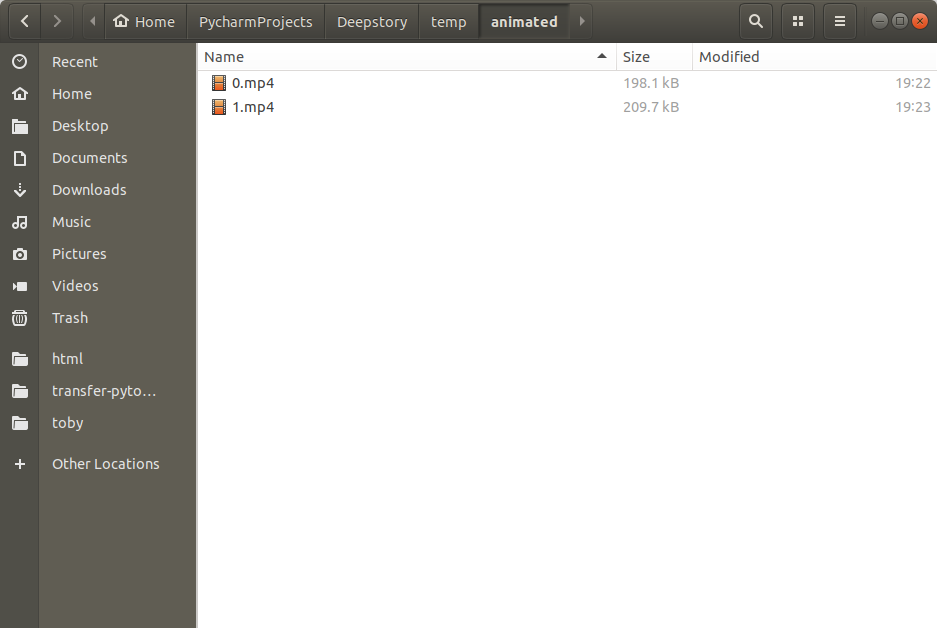
The animate_image class inside deepstory class becomes:
with ImageAnimator() as animator:
for i, base_path in enumerate(sorted(glob.glob('temp/base/*'))):
speaker = os.path.splitext(os.path.basename(base_path))[0].split("|")[1]
animator.animate_image(
f'data/images/{image_dict[speaker]}',
np.load(base_path),
f'temp/animated/{i}.mp4'
)And the other thing I need to mention is, during the combine_wavs method in deepstory class, the combined audio isn’t stored in memory as an array anymore, but written directly to export folder(it’s required later when creating the video with ffmpeg)
This code is added to write the wav file:
scipy.io.wavfile.write('export/combined.wav', hp.sr,
np.concatenate([wavs_dict['wav'] for wavs_dict in wavs_dicts], axis=None))Finally, I abandoned the save_video function from sda class, and I just look up some documentation of ffmpeg, and concatenate all the video first, then create a completed video from the exported combined audio and video.
audio = ffmpeg.input('export/combined.wav')
videos = [ffmpeg.input(clip) for clip in sorted(glob.glob('temp/animated/*'))]
ffmpeg.concat(*videos).output('export/combined.mp4', loglevel="panic").overwrite_output().run()
video = ffmpeg.input('export/combined.mp4')
ffmpeg.output(video['v'], audio['a'], 'export/animated.mp4', loglevel="panic").overwrite_output().run()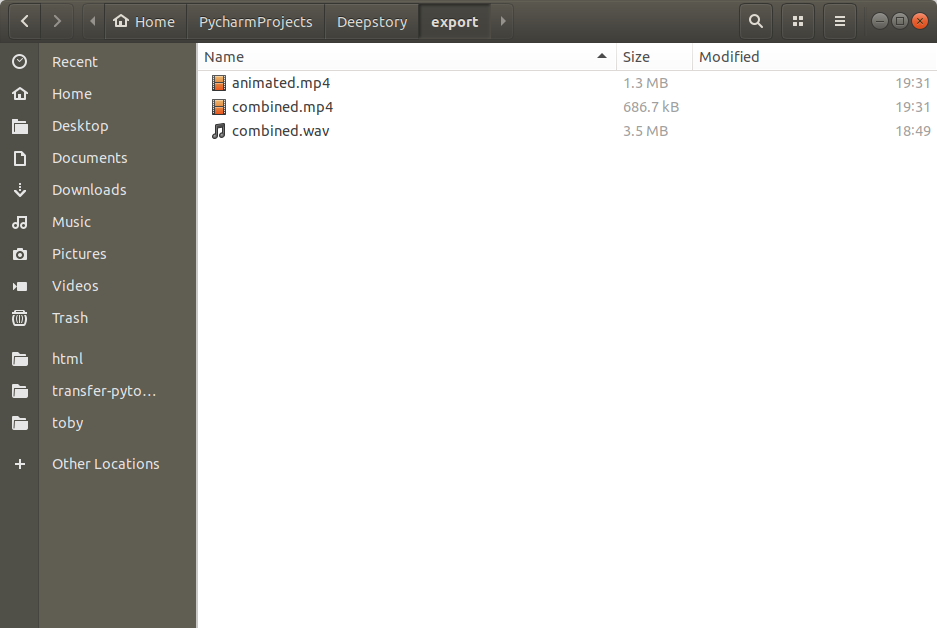
Now it’s done! Yeah.