I choose to work with epub format of ebook because they can be parsed as XML files and I can use a popular XML parser called BeautifulSoup in Python to extract data intelligently. And to read to epub files, I used a library called ebooklib.
I’ve looked at the documentation and figured out how to use it in my way. There weren’t many complicated things needed, basically, I need those:
- book.get_metadata()
- book.spine
- book.get_item_with_id(chapter).get_content()
Here is a notebook exploring the content and format inside a epub file: Here
Something to mention from the notebook is that the epub files has the main content labelled as different chapters, therefore, I need to figure out which chapters are used.
For example, the book has chapters named this:
book.spine
[('cover', 'no'),
('titlepage', 'yes'),
('welcome', 'yes'),
('epigraph', 'yes'),
('chapter001', 'yes'),
('chapter002', 'yes'),
('chapter003', 'yes'),
('chapter004', 'yes'),
('chapter005', 'yes'),
('chapter006', 'yes'),
('chapter007', 'yes'),
('appendix002', 'yes'),
('personblurb', 'yes'),
('teaser001', 'yes'),
('teaser002', 'yes'),
('chapter009', 'yes'),
('chapter010', 'yes'),
('ad-card', 'yes'),
('orbitnewsletter', 'yes'),
('toc', 'yes'),
('copyright', 'yes')]The chapter begins with chapter* should be the content we need, strangely, there are chapters after chapters called teaser. Even though there’s only 8 books, I want to make this programmable. I’ve figured to extract items that are consecutive so that only chapter001-007 will be extracted. And chapter009-010 is a preview for another book, which we don’t need.
chapter_list = []
for i, x in enumerate(spine_list):
if 'chapter' in x or 'epilogue' in x:
if chapter_list:
if spine_list.index(chapter_list[-1]) + 1 == i:
chapter_list.append(x)
else:
chapter_list.append(x)This is the code to extract chapter names from the book.spine that are only consecutive. After that, I just need to call
BeautifulSoup(book.get_item_with_id(chapter).get_content(), 'lxml')to parse the xml content.
So basically beautiful soup would parse all the tags into ‘objects’ like structure in Python. So after looking at the XML raw content, I can tell that the stuff is inside the <section> tag. Interestingly, some books have a format of big chapters and smaller chapters, while some books only have a bunch of small chapters. Hence, I have to write the program to recognize the books in either mode.
So breaking down the code in parse.py from the books project:
book_dict = {}
chapter_number = ''
chapter_title = ''
alt_mode = Falsefor chapter in chapters:
content = []
sect = ''
for tag in chapter.find('section'):
if type(tag) is not NavigableString:
if tag.text and tag.text != '\n' and tag.text != '\xa0':
tag_classes = tag.get('class', [])The book_dict is used for the current book, while chapter_number and chapter_title will be replaced as a new one when a new tag is found with a certain condition. So the idea is to use this as a cache to indicate the current status, and when a new chapter_number or chapter_title is found, the stuff inside content will be appended to respective key in book_dict and start the new one.
this part is to loop inside the section tag and confirm it is a tag, not just some plain text. Then, to confirm there is text inside the tag and it’s not blank space/return/strange stuff. Then the classes of the current tag inside the section tag(could be <h1> or <a>) is stored as tag_classes.
if any('part-title' in x for x in tag_classes):
alt_mode = True
chapter_title = tag.text
if chapter_title not in book_dict:
book_dict[chapter_title] = []Here is the beginning of an if statement, if part-title is found in the classes since that is a special case that only happens on some modes, alt_mode is activated and the chapter_title is the content of the current text. And chapter_title will be added to book_dict if not already exist.
elif any('chapter-number' in x for x in tag_classes):
if alt_mode:
if chapter_number != tag.text and content:
content = []
chapter_number = tag.text
else:
chapter_title = tag.text
if chapter_title not in book_dict:
book_dict[chapter_title] = []Continued from the if statement, if chapter-number is found instead in the classes since it exists in both modes, the behavior changes when alt mode is activated. Chapter-number indicates the label of the current chapter since some books use only I, II as name, or some books use it as sub-chapters, If it’s in alt mode, the current chapter_number will be replaced by this tag. And if not, chapter_title is used to create a new entry in book_dict instead of part-title from the previous part.
elif any('chapter-title' in x for x in tag_classes):
if chapter_title:
del book_dict[chapter_title]
chapter_title = tag.text
if chapter_title not in book_dict:
book_dict[chapter_title] = []If chapter-title is found inside the tag_classes, it indicates that it is the current book chapter title, and a new key is created in book_dict. if it already exists, it will be replaced.
elif any('sect1' in x for x in tag_classes):
if sect != tag.text and content:
book_dict[chapter_title].append('\n'.join(content))
content = []
sect = tag.textThis part of code is more for The Last Wish book, each chapter contains different sections named I, II, III… etc. And this indicates the current chapters.
elif any(any(y in x for y in ['chap', 'epigraph', 'page-break', 'pb'])
for x in tag_classes
) or any([tag.select(f'[class*="{x}"]')
for x in ['attribution', 'decoration-rw10', 'dl']]):
passThis part has more to do with skipping the current tag, that means if it has a class that contains text ‘chap’, ‘epigraph’,… it will be skipped.
else:
content.append(tag.text)if the tags doesn’t fall into any one of the above condition, it is a normal tag containing text and and content(.text) will be appended to the content list.
After looping all the tags inside a chapter, the following code is executed. It also happens that some parts are in fact extended across ‘chapters’ in epub, and therefore it’s possible to stack the content list for more than one chapter in the chapter_list from book.spine to be appended.
if chapter_title:
book_dict[chapter_title].append('\n'.join(content))
if not alt_mode:
chapter_title = ''If the current chapter has chapter_title, it will append it to the book_dict. So it’s possible that the next chapter doesn’t have chapter_title, and the content will be stacked to the previous chapter_title since it didn’t change.
The following are some screenshots showing the progress and are easier to understand.
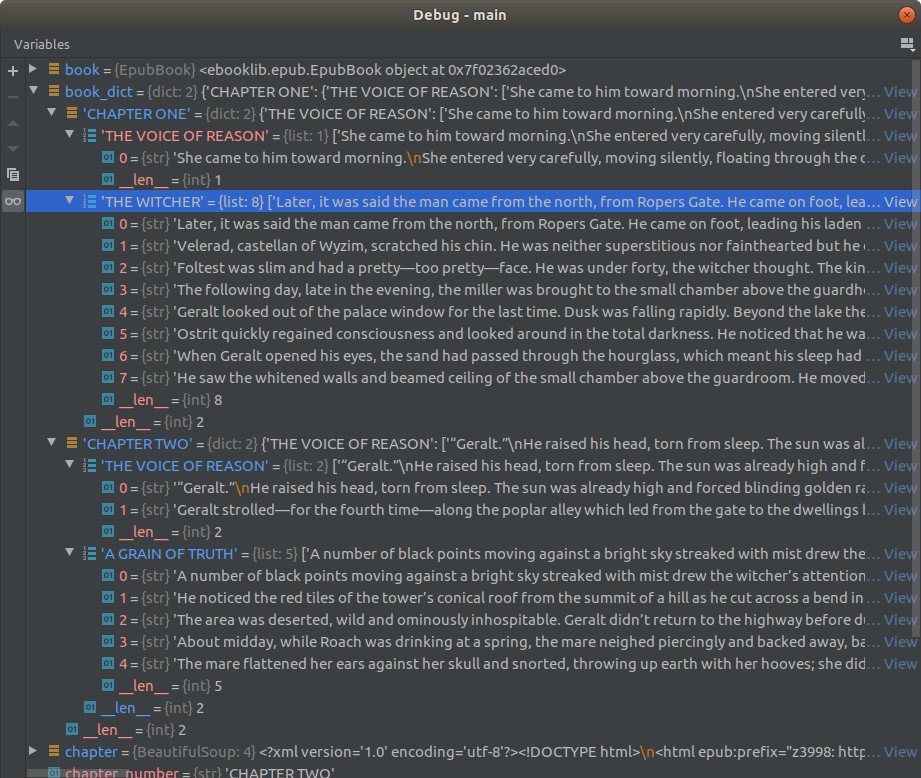



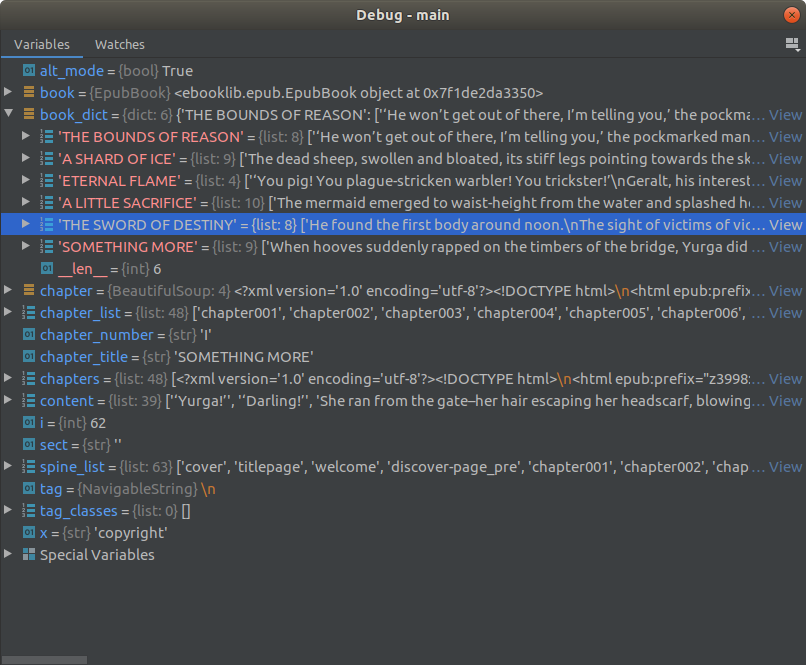

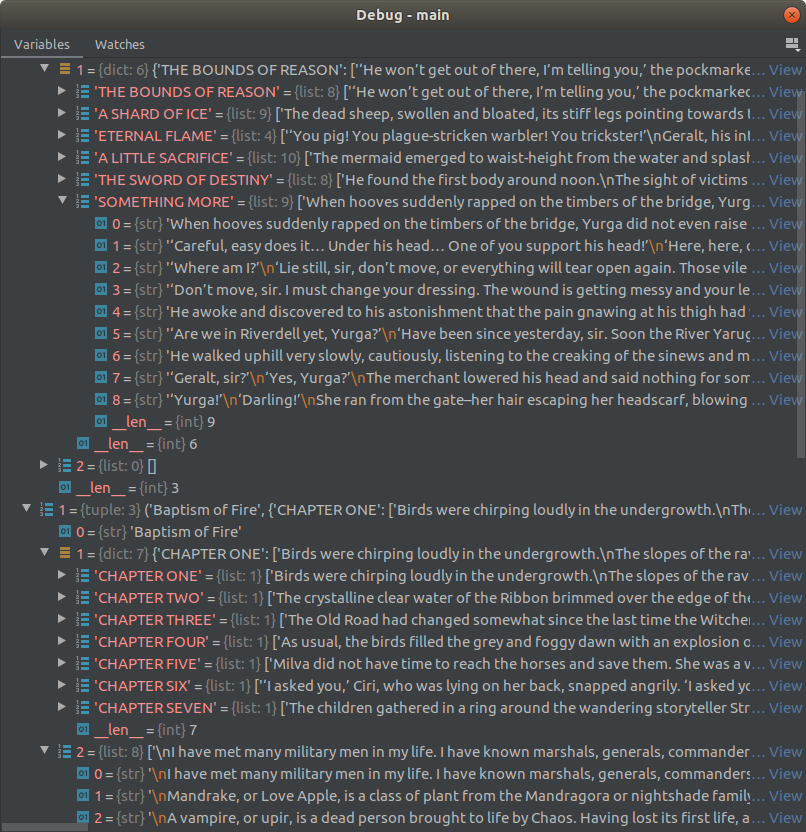

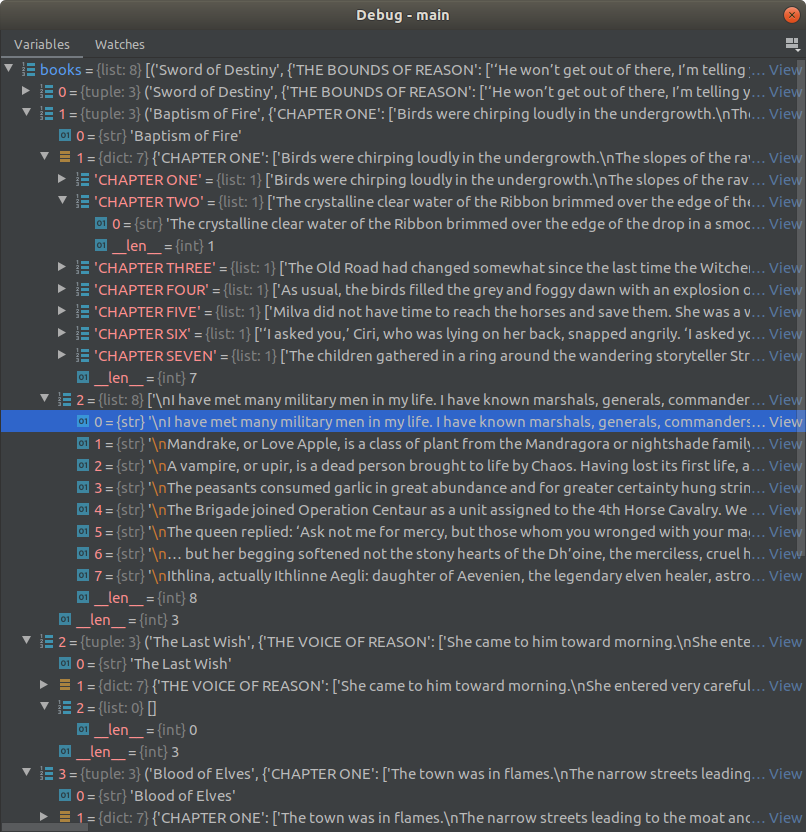
To run the codes for the books, the following codes are written:
books_list = glob.glob('books/*.epub')
books = [parse_book(book) for book in books_list]
texts = [chap for book in books for chap in book[1].values()]To prepare raw text into suitable format for GPT-2, I added the <|endoftext|> tokens. (<|startoftext|> is optional for gpt2-simple)
start_token = "<|startoftext|>"
end_token = "<|endoftext|>"
with open('witcher.txt', 'w', encoding='utf-8') as f:
for text in texts:
f.write(start_token + text + end_token + "\n")
print('done')