There were quite a lot of problems in the previous update:
All the unknown speaker is replaced by the default speaker. It makes no sense when there is multiple unknown speaker parsed in the main page. It doesn’t distinguish the speakers of the sentences. Hence I come up with a mapping structure.
The text normalization is already done when loading the sentence in the main panel instead of when it’s about to synthesize. It makes the punctuation intended in the original text goes away. And I have already written a function to extract the punctuation so that different duration of silences can be added when combining the audio.
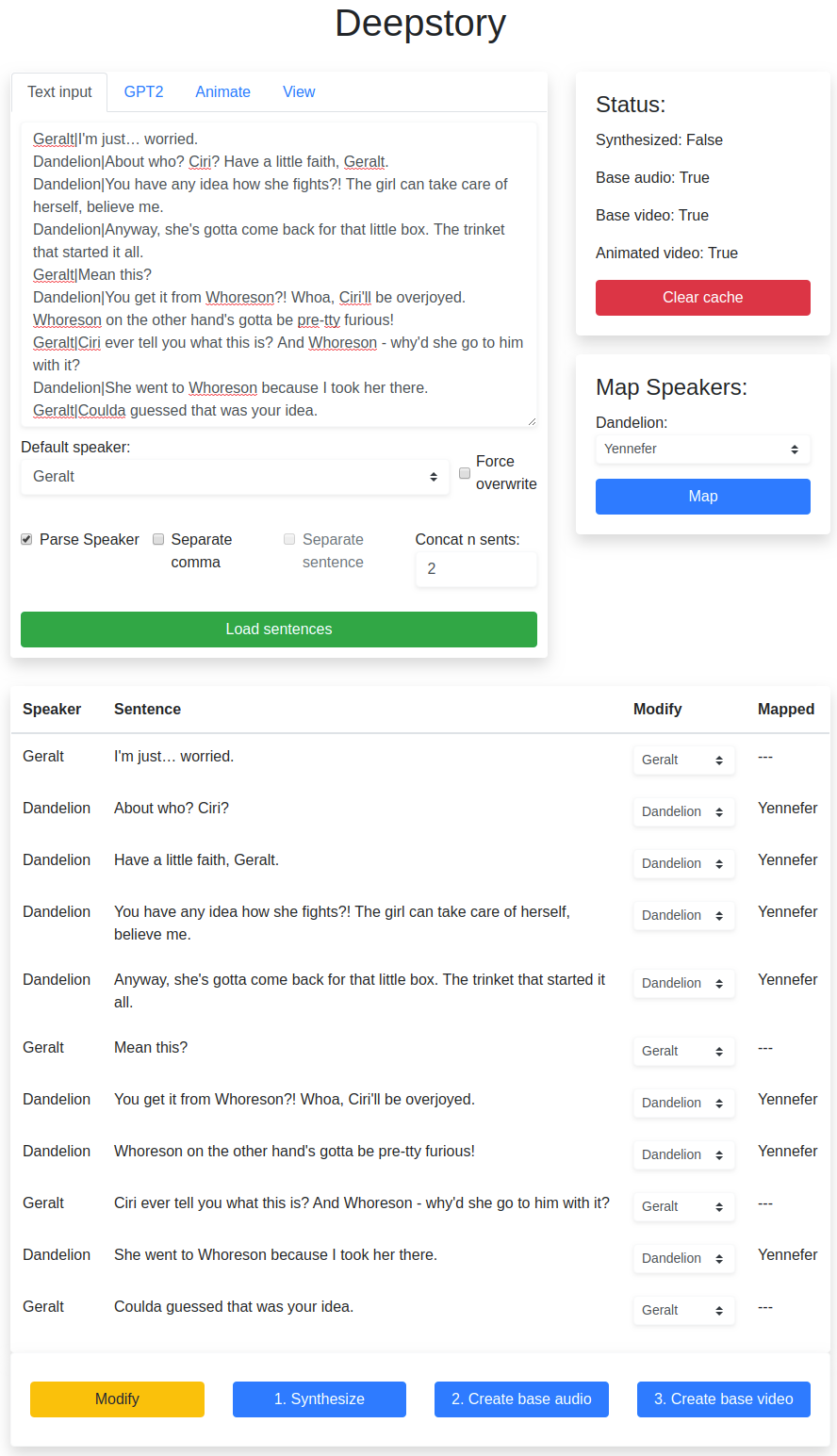

There was no creativity in GPT-2 part. It just generate the whole text and I hadn’t figured out the limitation. And later I studied more of the transformers library’s documentation and understand the true meaning of the max_length parameter. Firstly the sentences must be encoded to tokens, and the max_length means the maximum amount of tokens to be generated.
For example, a sentence “I like to swim.” would be encoded to four tokens. It’s also a habit that GPT2 combine the space found before a word into a single token. ” like” is one token. Hence it has five tokens:
[I][ like][ to] [swim][.]
Also, to generate 200 tokens, I will have to first calculate that amount of tokens found in the input(inferred) text and add 200 to pass to max_length.
For example, I entered a text and want to continue it, it already has 400 tokens. To generate 200 tokens, the max_length should be 400+200=600.
And the GPT-2 model can support only up to 1024 tokens, which means, if I have to maximize the inferred tokens when the input text exceed 1024 tokens, I should use the last [1024-genereated tokens] from the original text, so that the remaining space is reserved for generation and it will not exceed 1024.
To make this more interactive, it’s now possible to generate the next sentence. The logic is that, followed by the input of generating a whole text, it now also needs a parameter to define how many batch and how many sentences will be trimmed from the generated content. Hence, it doesn’t really generate a specific amount of sentences, but first generate a bunch of text according to the “Predict tokens” and trimmed to only the first n sentences(defined by .!?). A table is created after generation, and click the + button will automatically update the text loaded in the deepstory class.
Apart from that, the caching system now extend to audio combining part, and still, the previewed audio is still stored in ram and ready to be “streamed” when the table is rendered on the page.
The audio combining code is also modified completely, instead of merging the same speaker like from the previous code, now the audio is loaded in the model every sentences(line to be precised, cause each line contains multiple sentences). And within an inseparable audio synthesized from multiple sentences(for consistency), the audio is split again. The reason for splitting it is that I found out long audio doesn’t produce good speech to facial animation video. The model was trained a relatively short video clips and doesn’t do well with long sentences. The problem now is also with so many videos to be generated from each audio file, the video looks stuttered. So a balanced approach would be to calculate the audio duration and make sure it doesn’t exceed a certain threshold.